

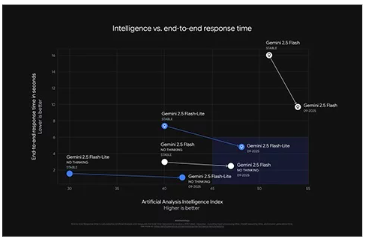
谷歌 Gemini 系列迎来重要更新,以 Gemini 2.5 Flash Lite 为代表的新模型在速度、成本与体验上实现全面进阶。这款模型的输出速度提升 40%,每秒可处理 887 个 token,成功登顶专有模型速度榜单。
效率提升成为本次更新的核心亮点:Flash Lite 版本通过技术优化,将输出 token 量削减 50%,结合其稀疏混合专家架构带来的资源高效利用特性,有效降低了计算成本与部署门槛。与此同时,模型输出质量并未因效率提升打折扣,实现了 “提速降本不减质” 的目标。值得一提的是,增强后的 Gemini Live 进一步优化了语音交互体验,不仅函数调用更可靠,还能更好地处理自然对话场景,为多模态应用开发提供更强支撑。
.
.
.
