

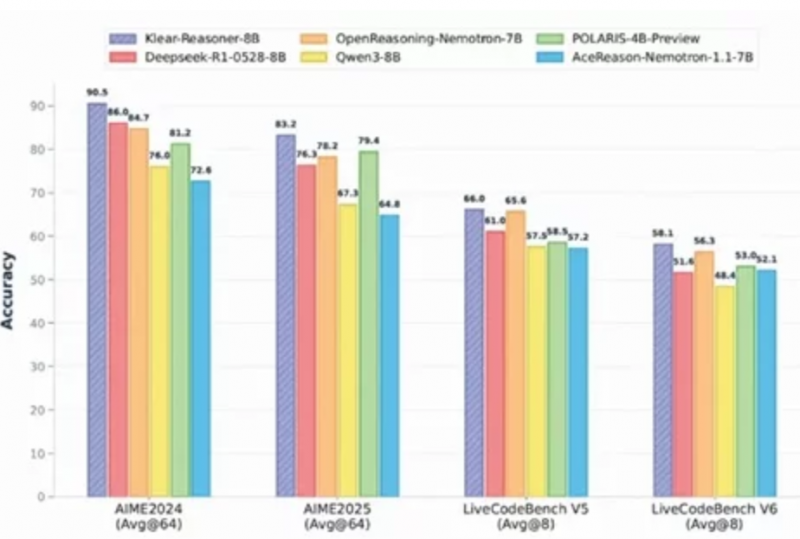
快手正式发布了 Klear-Reasoner 模型,该模型在数学推理领域表现亮眼,准确率成功突破 90%,超过了同规模的其他模型,处于领先地位。
在技术层面,它采用 GPPO 算法对梯度进行温和处理,这样既能保留一定的探索空间,又能加快对错误的修正速度。在 AIME2024 测试中,该模型取得了 90.5% 的高分,充分展现了其强大的数学推理能力。
训练过程中,团队格外注重数据质量,会过滤掉错误样本,同时在强化学习中运用软奖励策略。优质的数据源有效提升了模型的表现,不仅推动了 AI 推理领域的发展,也为其他模型的研发提供了可借鉴的经验。
.
.
.
.
.
.
